.gif)
El acrónimo ADN (Ácido desoxiribonucleico; DNA en inglés) ha traspasado el dominio de los términos técnicos y especializados para convertirse en un icono cultural, algo que a todo el mundo le suena y que hasta se puede usar metafóricamente en frases hechas («lo lleva en su ADN»). La popularización de un término científico es, por supuesto, algo muy positivo, pero también conlleva un mayor peligro de que se haga mal uso de éste, al no conocerse de él apenas algo más que el propio acrónimo. Ese es uno de los motivos por los cuales es tan necesario divulgar y extender un conocimiento básico sobre qué es el ADN por toda la población. Otro motivo es, claro está, el hecho de que el ADN sea una entidad tan fundamental y relevante, tanto a un nivel biológico como a un nivel tecnológico.
Las «grandes preguntas» (¿quiénes somos? ¿de dónde venimos?) pasan por el ADN y por un cierto grado de entendimiento sobre qué es esta molécula y qué papel (¡esencial!) ha jugado en nuestra evolución y en nuestra naturaleza. Además, el ADN posee una gran importancia más allá del dominio de la curiosidad intelectual que nos lleva a querer entender el mundo a nuestro alrededor: las modernas tecnologías médicas y forenses basadas en el ADN hacen que la biología molecular tenga más que nunca un impacto de peso sobre nuestras vidas de una manera muy concreta y palpable. Así pues, en este artículo nos planteamos dar una visión básica sobre qué es el ADN, cómo se descubrió y por qué es tan importante.
Historia del descubrimiento
Siempre debe de haber sido obvio para los humanos que los hijos tienden a tener algunas similitudes físicas e incluso de carácter con sus madres y padres. Este hecho se normalizó tanto que dejó de resultar misterioso ―como con todas las cosas que no comprendemos y que incorporamos automáticamente al conjunto de fenómenos que nos parecen intuitivos―, y, sin caer en el sesgo de confirmación, encontramos continuamente parecidos entre miembros de una misma familia, confirmando continuamente en la experiencia que existe la herencia biológica.
Charles Darwin, gigante científico que fue unos de los descubridores y desarrolladores de la Teoría de la Evolución, fue uno de los primeros en plantear el hecho de la herencia biológica como un misterio que había que atacar científicamente. Tras proponer el mecanismo de evolución por selección natural, según el cual tienen más oportunidades de sobrevivir aquellos individuos con características adaptadas más idóneamente al medio, Darwin razonó que tenía que existir algún proceso físico por el cual un padre y una padre trasmitían sus características a su descendencia. Más aún, argumentó Darwin, tenía que existir cierto componente de aleatoriedad y volatilidad en ese mecanismo de transferencia, pues de otro modo no se explicaría la aparición de la variabilidad, elemento esencial en la evolución de las especies.
Esos componentes aleatorios son las mutaciones: errores en la copia de la información a la descendencia fruto del azar o la influencia de agentes externos. Normalmente, esos errores azarosos serán perjudiciales y, quizá, incluso letales. Pero, aunque muy improbable, de vez en cuando uno de esos “errores” introduce una diferencia que resulta ventajosa para el individuo. Si ese individuo tiene más éxito para adaptarse a su entorno y sobrevivir y reproducirse, puede que ese “error” poco a poco empiece a imponerse y a convertirse en una característica canónica de la especie. Pero, ¿cómo eran exactamente esos elementos materiales que permitían la transmisión de características de madres y padres a hijos?
Otro científico quizá tan popular como Darwin durante nuestros años de instituto fue el monje Mendel, que en la decada de los sesenta del siglo XIX enunció unas leyes acerca de cómo se producía la herencia. Las leyes de Mendel fueron luego integradas en un marco teórico más amplio por Morgan e incluso matematizadas por el gran estadístico Ronald Fisher, uno de los creadores de la genética de poblaciones. Estas leyes, sin embargo, no acercaron a los científicos en absoluto a averigüar la base material de la herencia. Uno de los primeros pasos en este sentido lo dió el suizo Fiedrich Miescher en 1869 al aislar lo que él llamó nucleína, el componente químico del núcleo de la célula. Miescher murió al final del siglo, así que probablemente no llegó a preveer la trascendencia de su descubrimiento, aunque si que llegó a afirmar que la nucleína podía tener algo que ver con la herencia.
Fue el premio Nobel alemán Albrecht Kossel quien, apoyándose entre muchos otros en el trabajo de Miescher, logró distinguir en la nucleína un componente proteíco y uno no proteíco que poseía un intrigante carácter ácido. A este segundo componente se le llamó ácido nucleico, y su descubrimiento sentó las bases de la resolución del misterio de la herencia. Kossel, además, aisló por primera vez las llamadas bases nitrogenadas, de las que hablaremos más adelante.

Avery en su laboratorio
Debido a la escasez del tipo de bases nitrogenadas (sólo hay cuatro tipos), se pensó durante mucho tiempo que los ácidos nucleicos no podrían ser la base de la herencia, y que eran las proteínas (que presentan, en principio, una variabilidad mucho mayor) las macromoléculas capaces de almacenar y trasmitir la información de la herencia. Erwin Schrödinger llegó a expresar esta convicción en su famoso libro Qué es la vida, que animó a muchos físicos teóricos (como al mismo Francis Crick) a pasarse al campo de la biología molecular al tratar de hacer una descripción de la vida desde el punto de vista de la física y la termodinámica. Fue por tanto un descubrimiento muy sonado cuando en 1943, mismo año de la publicación del librito de Schrödinger, un famoso experimento de Avery, MacLeod y McCarty demostró que el ADN era el material genético responsable de las transformaciones en bacterias. Este hecho fue definitivamente corroborado por Hershey y Chase nueve años más tarde.
El descubrimiento del ADN, de sus propiedades y de sus características es una proeza técnica en tanto que supone manipular objetos diminutos con gran precisión. Las células, los constituyentes vivos más pequeños que existen y cuyas agrupaciones en conjuntos especializados dan lugar a la vida macroscópica como la conocemos, son ya de por sí entidades diminutas cuya realidad no se intuyó hasta la invención del miscroscopio. El ADN va varios pasos más allá en escalas de pequeñez. Hay que manipular los componentes del núcleo de la célula para poder aislar y estudiar la molécula de ácido desoxiribonucleico, como se esquematiza en la siguiente imagen:
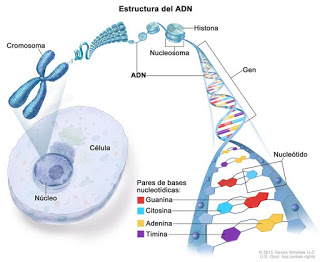
De la célula al ADN
El punto álgido en la historia del descubrimiento de las bases químicas del ADN vino al comienzo de la década de los cincuenta, cuando se logró desentreñar la estructura exacta de la molécula. En una carrera agobiante por el descubrimiento llena de tropiezos, bajezas y proezas, unos científicos de Cambdrige se adelantaron al equipo de Linus Pauling que trataba de resolver el mismo problema. ¡Si Pauling hubiese «ganado», es de suponer que se habría convertido en el único ser humano en haber recibido tres premios Nobel!
James Watson, Francis Crick, Rosalind Franklin y Maurice Wilkins publicaron (por separado) distintos artículos que son hoy la base del entendimiento de la estructura del ADN. Hay, por supuesto, muchísimos científicos que realizaron aportaciones esenciales, pero resulta imposible mencionarlos a todos con justicia, lo cual debería ser el propósito de un texto histórico más profundo y específico. Franklin llevó a cabo unos experimentos de cristalografía de rayos X en una época en que la cristalografía con biomoléculas era un campo desconocido ―otra cristalógrafa, Dorothy Crowfoot Hodgink, ganaría el Nobel en 1969 por sus trabajos fundamentales en este campo―, y obtuvo unas imágenes novedosas que fueron la base para que Watson y Crick pudieran acabar realizando su modelo de la doble hélice.
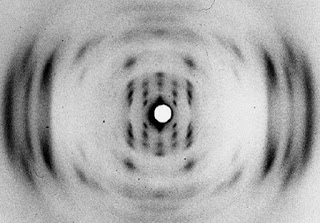
Fotografía del ADN obtenida por Rosalind Franklin en el laboratorio
En 1962, Watson, Crick y Wilkins recibieron el premio Nobel por su trabajo. Desgraciadamente, Franklin había muerto poco antes de un cáncer de ovario y nunca llegó a conocer la trascendencia de su trabajo. Hay toda una polémica en torno a la falta de reconocimiento que sus tres compañeros le brindaron, aunque afortunadamente a día de hoy se puede considerar que Franklin ha obtenido un extraordinario reconomiento, al menos en el contexto del mundo académico. Está claro que sin el trabajo fundacional de Franklin el éxito de Watson y Crick habría sido imposible. Afortunadamente se ha reconocido ya el mérito de una científica sobresaliente que tuvo que lidiar con prejuicios y estereotipos indeseables manteniendo la pasión y el placer por descubrir.

Rosalind Franklin, en fotografías tomadas a principio de los cincuenta
¿De qué está hecho el ADN?
Al igual que el acrónimo ADN, el término “doble hélice” ha pasado a la historia no sólo en la literatura especializada sino entre el gran público. Una representación esquemática y poco detallada de la geometría de la molécula del ADN será reconocida inmediatamente por casi cualquier persona como precisamente eso, la doble hélice del ADN, o al menos como algo científico que tiene que ver con la biología y la herencia.
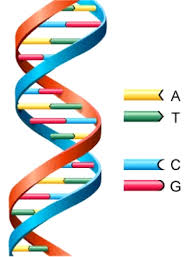
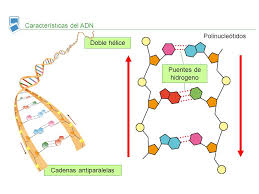
La famosa doble hélice, en representación esquemática. Las letras A,T,G y C denotan a las cuatro bases nitrogenadas (adenina, timina, guanina, citosina)
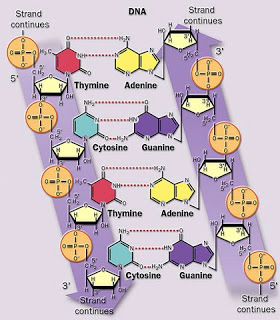
Las hebras helicoidales están compuestas por unidades alternadas de ácido fosfórico y de un tipo de azúcar llamado desoxirribosa (el azúcar ribosa sin un átomo de oxígeno) unidas covalentemente.
Estas moléculas son la base estructural del esqueleto de la molécula: son como vigas metálicas sosteniendo una estructura. Para hacer una idea de las dimensiones de las que estamos hablando, diremos que una de estas hebras da un giro de 360º cada tres y media milmillonésimas de metro, y que en cada célula de nuestro cuerpo podemos encontrar metros de ADN.
Este esqueleto en forma de doble hélice, aun siendo el agente esencial que da estructura y soporte al ADN, es en cierto sentido sólo un actor secundario en el misterio de la herencia: el código para la vida está escrito en las secuencias de las llamadas bases nitrogenadas, moléculas que se encuentran unidas a ambas hebras también mediante enlaces covalentes fuertes. Las bases nitrogenadas apuntan más o menos perpendicularmente desde la hebra a la que están unidas y hacia la complementaria. En cada vuelta completa de la doble hélice podemos encontrar diez pares de bases.
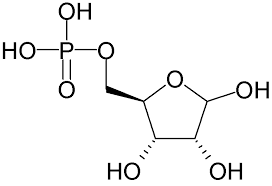
El ácido fosfórico, arriba a la izquierda, y la molécula de ribosa, unidos covalentemente a través de un enlace oxígeno-carbono
En el ADN encontramos exactamente cuatro tipos de estas bases nitrogenadas: la adenina y la guanina (purinas), y la timina y la citosina (pirimidinas). Por brevedad, nos referiremos en todo momento a las bases por sus iniciales en mayúscula: A, G, T y C. Por una cuestión de afinidad química, siempre que en una posición de un
a de las hélices aparece una A, en la hélice de enfrente aparece una T, y siempre que aparece una G enfrente ha de aparecer una C. Ésta es la complementariedad de las bases nitrogenadas y una ley básica que siguen las dobles hélices del ADN. Así, si en una vuelta de una hebra encontramos la secuencia de bases ATGCCAGCTC en la hebra complementaria encontraremos TACGGTCGAG.
Representación esquemática del ADN
Esta complementariedad quiere decir que, a efectos de almacenar información, en el ADN hay material redundante. Existe, sin embargo, ADN de una sola hebra, aunque en todas las células eucariotas y seres vivos pluricelurales el material genético es almacenado en esta estructura de doble hélice donde dos hebras complementarias se aparean.
El código genético
¿Cómo puede una secuencia de cuatro elementos almacenar la información hereditaria necesaria para que un hijo tenga los ojos de su madre o la nariz de su padre? ¿De qué manera una sucesión de tan diminutas moléculas puede contener las instrucciones para nuestro desarrollo? La respuesta es que esta información está cifrada.
Imaginemos que yo decido representar cada letra del alfabeto por una secuencia de unos y ceros (la “a” con el 1, la “b” con el 10,…, la “h” con el 1000… ¡hay un patrón bastante claro que seguir, aunque cada uno puede inventarse el que quiera!). En ese caso, cualquier frase podría pasarse a una sucesión de unos y ceros. Podríamos convenir en representar todas las letras con secuencias de longitud seis, poniendo ceros
Representación esquemática del discurrir antiparalelo de las dos hebras helicoidales. Arriba y al final de la imagen, se indica que las hebras siguen discurriendo en el sentido de las flechas (“Strand continues”)
a la izquierda cuando hiciese falta, de modo que no habría ambigüedad sobre la longitud de las secuencias al yuxtaponer distintas letras. Quizá convendríamos, también, en escoger una secuencia específica (digamos, 111110) para designar una coma, y otra (111111) para indicar un punto.
Con el ADN pasa algo parecido: A, G, T y C serían las cifras. ¿Cuáles son las letras, las palabras y la longitud de las secuencias? Las letras son otro tipo de moléculas esenciales, los aminoácidos, que son los constituyentes “atómicos” de las proteínas (nuestras “palabras” o “frases”), esas macromoléculas ubicuas que son los agentes y herramientas protagonistas de todos los fenómenos importantes para la vida. Resumiendo y sin entrar en complicaciones (nos permitimos mentir ligeramente, a fin de no sobrecargar la explicación), una proteína es una secuencia de aminoácidos (recordemos, las “letras”) que se pliega y se dobla de maneras complejísimas, adoptando una estructura geométrica altamente específica que le permite llevar a cabo una función muy concreta.
Hay decenas de miles de tipos de proteínas y cada una, en efecto, lleva a cabo una función muy especializada. Sin las proteínas, literalmente no existirían estructuras biológicas ni se llevaría a cabo ninguno proceso relacionado con la vida y su funcionamiento a ningún nivel. Las proteínas, pues, son las máquinas que hacen posible la vida. El mecanismo de la herencia, dicho de una manera breve, consiste en un método eficaz y seguro de trasmitir a la descendencia la información necesaria para sintetizar esas mismas proteínas que permitieron la supervivencia y el éxito reproductivo de los progenitores. Ese método eficaz y seguro es (¡sorpresa!) la doble hélice del ADN con sus secuencias complementarias de bases nitrogenadas.
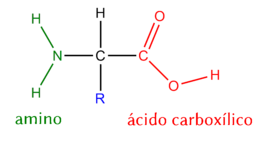
Estructura genérica de un aminoácido.
Hay exactamente veinte tipos de aminoácidos que juegan un papel en la vida en la tierra, y son las secuencias de miles de éstos (unidos linealmente por enlaces fuertes de tipo covalente –los llamados enlaces peptídicos-) y la manera en que éstas se pliegan obedeciendo las leyes de la física y la química lo que forma las proteínas. Una secuencia de tan sólo mil letras con un alfabeto de veinte caracteres da ya un total de veinte elevado a mil (20^1000) posibles proteínas, lo que ya es un número colosal e inmanejable. El número de posibilidades reales es, claro está, aún muchísimo mayor, e intentar imaginarlo puede dar una idea de la tremenda complejidad del funcionamiento de la vida a este nivel molecular tan básico.
Ya hemos dicho que, si los aminoácidos son las “letras”, las bases nitrogenadas son las “cifras” con que las codificamos. Pero, ¿de qué longitud han de ser las secuencias determinando una sóla letra? Desde luego no puede ser longitud 1, pues 4 es menos que 20 (que, recordemos, es el número de aminoácidos que se encuentran en los organismos vivos). Y, como 4 elevado a 2 es 16, aún menor que 20, la respuesta tampoco puede ser longitud 2. 4 elevado a 3 es 64, un número ya suficientemente alto. Y, efectivamente, la respuesta de la naturaleza es 3: una secuencia de tres bases nitrogenadas codifica para un aminoácido concreto. Por supuesto, siendo 64 más de tres veces 20, hay varios tripletes (una secuencia de tres bases nitrogenadas) correspondiendo a un solo aminoácido, e incluso hay secuencias que quieren decir “fin de secuencia”. Ahora bien, ¿cuál es la traducción completa de aminoácidos a secuencias de bases? ¿Sabemos el código de cifrado usado por la naturaleza? Pues resulta que sí, esto se sabe y se pueden resumir de forma bastante conveniente en una tabla:
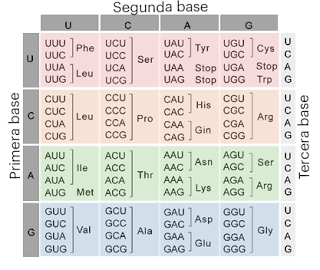
El código genético
Esto es lo que se conoce como código genético: es un diccionario atómico que nos explicita qué secuencias de bases están asociadas a qué aminoácidos. Al ver una tabla como la de arriba, uno quizá se pregunte exactamente a qué organismo corresponde ese diccionario. ¿Es ése el código genético de los humanos? La respuesta es, a impresión del que escribe estas líneas, una de las más asombrosas y petrificantes que la ciencia ha dado jamás: Ese diccionario es, salvo excepciones puntuales, el mismo para todo organismo viviente sobre el planeta tierra. En otras palabras: el código genético es universal.
No importa si eres un roble, un salmón, o un ser humano; el triplete ATG codifica una metionina (un tipo de aminoácido). Y esto, en efecto, es un recuerdo fascinante de que robles, salmones y seres humanos tenemos un origen común. Uno de los protagonistas en el desciframiento de este código de la naturaleza, de este secreto de la vida, es el Nobel de Medicina español Severo Ochoa, aunque por supuesto hay muchos otros, como Crick, Brenner, Khorana, Holley, Nirenberg y Leder (el premio Nobel de 1968 fue para Khorana, Holley y Nirenberg).

Severo Ochoa, Nobel de Medicina
Llegados a este punto, es ya obvio, aún sin haber profundizado en cuestiones técnicas, el papel central que el ADN ha jugado y aún juega en el fenómeno de la vida. La famosa doble hélice y sus bases nitrogenadas representan uno de los “secretos de la vida”, como exclamara Francis Crick emocionado al entrar en el Pub The Eagle en Cambdrige. Pero la importancia del ADN no se queda ahí. Aún para alguien sin inquietudes por entender la naturaleza y las intimidades de la vida, el ADN y nuestra moderna capacidad para manipularlo pueden ser crucial a la hora de condenarle por asesinato o salvarle la vida.
Por otra parte, las terapias génicas, basadas en refinamientos cada vez más profundos del dominio de la biotecnología, prometen no ya sólo un cambio de paradigma en medicina, sino también una profunda transformación social. Hoy en día, la investigación sobre el ADN es además un campo transversal y multidisciplinar, que da cabida a profesionales de la biología, medicina, química, física o informática. Hacer ordenadores que funcionan con moléculas de ADN en lugar de con silicio; o literalmente cortar y pegar genes a nuestro antojo: éstas son algunas de las cosas que ya son una realidad y cuyas implicaciones en el futuro cercano son irresistibles para la imaginación.
Artículo publicado originalmente en el blog Las Dos Sombras. Adaptado para la revista FUA